Excercises¶
UW Geospatial Data Analysis
CEE498/CEWA599
David Shean
Objectives¶
Solidify basic skills with NumPy, Pandas, and Matplotlib
Learn basic data manipulation, exploration, and visualizatioin with a relatively small, clean point dataset (65K points)
Learn a bit more about the ICESat mission, the GLAS instrument, and satellite laser altimetry
Explore outlier removal, grouping and clustering
ICESat GLAS Background¶
The NASA Ice Cloud and land Elevation Satellite (ICESat) was a NASA mission carrying the Geosciences Laser Altimeter System (GLAS) instrument: a space laser, pointed down at the Earth (and unsuspecting Earthlings).
It measured surface elevations by precisely tracking laser pulses emitted from the spacecraft at a rate of 40 Hz (a new pulse every 0.025 seconds). These pulses traveled through the atmosphere, reflected off the surface, back up through the atmosphere, and into space, where some small fraction of that original energy was received by a telescope on the spacecraft. The instrument electronics precisely recorded the time when these intrepid photons left the instrument and when they returned. The position and orientation of the spacecraft was precisely known, so the two-way traveltime (and assumptions about the speed of light and propagation through the atmosphere) allowed for precise forward determination of the spot on the Earth’s surface (or cloud tops, as was often the case) where the reflection occurred. The laser spot size varied during the mission, but was ~70 m in diameter.
ICESat collected billions of measurements from 2003 to 2009, and was operating in a “repeat-track” mode that sacrificed spatial coverage for more observations along the same ground tracks over time. One primary science focus involved elevation change over the Earth’s ice sheets. It allowed for early measurements of full Antarctic and Greenland ice sheet elevation change, which offered a detailed look at spatial distribution and rates of mass loss, and total ice sheet contributions to sea level rise.
There were problems with the lasers during the mission, so it operated in short campaigns lasting only a few months to prolong the full mission lifetime. While the primary measurements focused on the polar regions, many measurements were also collected over lower latitudes, to meet other important science objectives (e.g., estimating biomass in the Earth’s forests, observing sea surface height/thickness over time).
Sample GLAS dataset for CONUS¶
A few years ago, I wanted to evaluate ICESat coverage of the Continental United States (CONUS). The primary application was to extract a set of accurate control points to co-register a large set of high-resolution digital elevation modoels (DEMs) derived from satellite stereo imagery. I wrote some Python/shell scripts to download, filter, and process all of the GLAH14 L2 Global Land Surface Altimetry Data granules in parallel (https://github.com/dshean/icesat_tools).
The high-level workflow is here: https://github.com/dshean/icesat_tools/blob/master/glas_proc.py#L24. These tools processed each HDF5 (H5) file and wrote out csv files containing “good” points. These csv files were concatenated to prepare the single input csv (GLAH14_tllz_conus_lulcfilt_demfilt.csv) that we will use for this tutorial.
The csv contains ICESat GLAS shots that passed the following filters:
Within some buffer (~110 km) of mapped glacier polygons from the Randolph Glacier Inventory (RGI)
Returns from exposed bare ground (landcover class 31) or snow/ice (12) according to a 30-m Land-use/Land-cover dataset (2011 NLCD, https://www.mrlc.gov/data?f[0]=category:land cover)
Elevation values within some threshold (200 m) of elevations sampled from an external reference DEM (void-filled 1/3-arcsec [30-m] SRTM-GL1, https://lpdaac.usgs.gov/products/srtmgl1v003/), used to remove spurious points and returns from clouds.
Various other ICESat-specific quality flags (see comments in
glas_proc.pyfor details)
The final file contains a relatively small subset (~65K) of the total shots in the original GLAH14 data granules from the full mission timeline (2003-2009). The remaining points should represent returns from the Earth’s surface with reasonably high quality, and can be used for subsequent analysis.
Lab Exercises¶
Let’s use this dataset to explore some of the NumPy and Pandas functionality, and practice some basic plotting with Matplotlib.
I’ve provided instructions and hints, and you will need to fill in the code to generate the output results and plots.
Import necessary modules¶
#Use shorter names (np, pd, plt) instead of full (numpy, pandas, matplotlib.pylot) for convenience
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#Magic function to enable interactive plotting (zoom/pan) in Jupyter notebook
#If running locally, this would be `%matplotlib notebook`, but since we're using Juptyerlab, we use widget
#%matplotlib widget
#Use matplotlib inline to render/embed figures in the notebook for upload to github
%matplotlib inline
#%matplotlib widget
Define relative path to the GLAS data csv from week 01¶
glas_fn = '../01_Shell_Github/data/GLAH14_tllz_conus_lulcfilt_demfilt.csv'
Do a quick check of file contents¶
Use iPython functionality to run the
headshell command on the your filename variable
NumPy Exercises¶
Load the file¶
NumPy has some convenience functions for loading text files:
loadtxtandgenfromtxtUse
loadtxthere (simpler), but make sure you properly set the delimiter and handle the first row (see theskiprowsoption)Use iPython
?to look up reference on arguments fornp.loadtxt
Store the NumPy array as variable called
glas_np
Do a quick check to make sure your array looks good¶
Don’t use
print(glas_np)here, just run cell containingglas_npTry both - note that the latter returns the object type, in this case
array
How many rows and columns are in your array?¶
What is the datatype of your array?¶
Note that a NumPy array typically has a single datatype, while a Pandas DataFrame can contain multiple data types (e.g., string, float64)
Examine the first 3 rows¶
Use slicing here
Examine the column with glas_z values¶
You will need to figure out which column number corresponds to these values (can do this manually from header), then slice the array to return all rows, but only that column
Compute the mean and standard deviation of the glas_z values¶
Use print formatting to create a formatted string with these values¶
Should be
'GLAS z: mean +/- std meters'using yourmeanandstdvalues, both formatted with 2 decimal places (cm-precision)For example: ‘GLAS z: 1234.56 +/- 42.42 meters’
Create a Matplotlib scatter plot of the glas_z values¶
Careful about correclty defining your x and y with values for latitude and longitude - easy to mix these up
Use point color to represent the elevation
You should see points that roughly outline the western United States
Label the x axis, y axis, and add a descriptive title
Pandas Exercises¶
A significant portion of the Python data science ecosystem is based on Pandas and/or Pandas data models.
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way towards this goal.
https://github.com/pandas-dev/pandas#main-features
If you are working with tabular data, especially time series data, please use pandas.
A better way to deal with tabular data, built on top of NumPy arrays
With NumPy, we had to remember which column number (e.g., 3, 4) represented each variable (lat, lon, glas_z, etc)
Pandas allows you to store data with different types, and then reference using more meaningful labels
NumPy:
glas_np[:,4]Pandas:
glas_df['glas_z']
A good “10-minute” reference with examples: https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
Load the csv file with Pandas¶
Note that pandas has excellent readers for most common file formats: https://pandas.pydata.org/pandas-docs/stable/reference/io.html
That was easy. Let’s inspect the DataFrame¶
Check data types¶
Can use the DataFrame
infomethod
Get the column labels¶
Can use the DataFrame
columnsattribute
If you are new to Python and object-oriented programming, take a moment to consider the difference between the methods and attributes of the DataFrame, and how both are accessed.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
If this is confusing, ask your neighbor or instructor.
Preview records using DataFrame head and tail methods¶
Compute the mean and standard deviation for all values in each column¶
Don’t overthink this, should be simple (no loops!)
Print quick stats for entire DataFrame with the describe method¶
Useful, huh? Note that median is the 50% statistic
Use the Pandas plotting functionality to create a 2D scatterplot of glas_z values¶
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.scatter.html
Note that labels and colorbar are automatically plotted!
Adjust the size of the points using the
s=1keywordExperiment with different color ramps:
https://matplotlib.org/examples/color/colormaps_reference.html (I prefer
inferno)
Color ramps¶
Information on how to choose a good colormap for your data: https://matplotlib.org/3.1.0/tutorials/colors/colormaps.html
Another great resource (Thanks @fperez!): https://matplotlib.org/cmocean/
TL;DR Don’t use jet, use a perceptually uniform colormap for linear variables like elevation. Use a diverging color ramp for values where sign is important.
Experiment by changing the variable represented with the color ramp¶
Try
decyearor other columns to quickly visualize spatial distribution of these values.
Extra Credit: Create a 3D scatterplot¶
See samples here: https://matplotlib.org/mpl_toolkits/mplot3d/tutorial.html
Explore with the interactive tools (click and drag to change perspective). Some lag here considering number of points to be rendered, and maybe useful for visualizing small 3D datasets in the future. There are other 3D plotting packages that are built for performance and efficiency (e.g., ipyvolume: https://github.com/maartenbreddels/ipyvolume)
Create a histogram that shows the number of points vs time (decyear)¶
Should be simple with built-in method for your
DataFrameMake sure that you use enough bins to avoid aliasing. This could require some trial and error (try 10, 100, 1000, and see if you can find a good compromise)
Can also consider some of the options (e.g., ‘auto’) here: https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram_bin_edges.html#numpy.histogram_bin_edges
You should be able to resolve the distinct campaigns during the mission (each ~1-2 months long). There is an extra credit problem at the end to group by years and play with clustering for the campaigns.
Create a histogram of all glas_z elevation values¶
What do you note about the distribution?
Any negative values?
Wait a minute…negative elevations!? Who calibrated this thing? C’mon NASA.¶
A note on vertical datums¶
Note that some elevations are less than 0 m. How can this be?
The glas_z values are height above (or below) the WGS84 ellipsoid. This is not the same vertical datum as mean sea level (roughly approximated by a geoid model).
A good resource explaining the details: https://vdatum.noaa.gov/docs/datums.html
Let’s check the spatial distribution of points below 0 (height above WGS84 ellipsoid)¶
How many shots have a negative glas_z value?
Create a scatterplot only using points with negative values
Adjust the color ramp bounds to bring out more detail for these points
hint: see the
vminandvmaxarguments for theplotfunction
What do you notice about these points? (may be tough without more context, like coastlines and state boundaries or a tiled basemap - we’ll learn how to incorporate these soon)
Geoid offset¶
Height difference between the WGS84 ellipsoid (simple shape model of the Earth) and a geoid, that approximates a geopotential (gravitational) surface, approximately mean sea level.
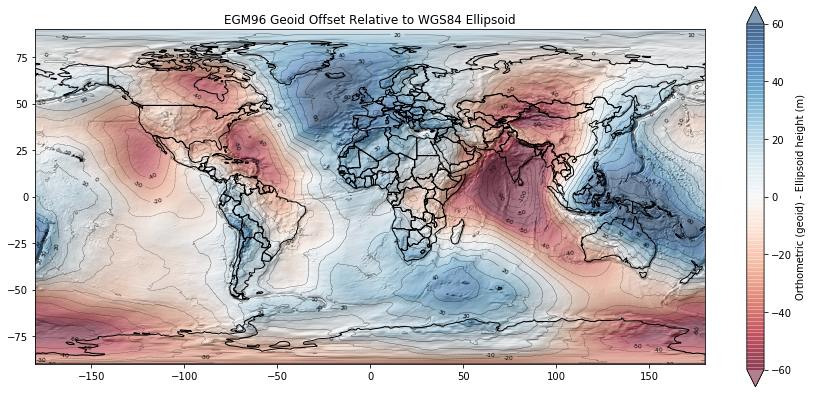
Note values for the Western U.S.
Interpretation¶
A lot of the points with elevation < 0 m in your scatterplot are near coastal sites, roughly near mean sea level. We see that the geoid offset (difference between WGS84 ellipsoid and EGM96 geoid in this case) for CONUS is roughly -20 m. So the ICESat GLAS point elevations near the coast will have values of around -20 m relative to the ellipsoid, even though they are around 0 m relative to the geoid (approximately mean sea level).
Another cluster of points with negative elevations is over Death Valley, CA, which is actually below sea level: https://en.wikipedia.org/wiki/Death_Valley.
If this is confusing, we will revisit when we explore raster DEMs later in the quarter. We also get into all of this in the Spring Advanced Surveying course (ask me for details).
Compute the elevation difference between ICESat glas_z and SRTM dem_z values¶
Earlier, I mentioned that I had sampled the SRTM DEM for each GLAS shot. Let’s compute the difference and store in a new column in our DataFrame called glas_srtm_dh
Remember the order of this calculation (if the difference values are negative, which dataset is higher elevation?)
Do a quick head to verify that the values in your new column look reasonable¶
Compute the time difference between ICESat point timestamp and the SRTM timestamp¶
Store in a new column named
glas_srtm_dtThe SRTM data were collected between February 11-22, 2000
Can assume a constant decimal year value of 2000.112 for now
Check values with
head
Compute apparent annualized elevation change rates (meters per year) from these new columns¶
This will be rate of change between the SRTM timestamp (2000) and each GLAS point timestamp (2003-2009)
Check values with
head
Create a scatterplot of the difference values¶
Use a
RdBu(Red to Blue) color rampSet the color ramp limits using
vminandvmaxkeyword arguments to be symmetrical about 0Generate two plots with different color ramp range to bring out detail
Do you see outliers (values far outside the expected distribution)?
Do you see any coherent spatial patterns in the difference values?
Create a histogram of the difference values¶
Increase the number of bins, and limit the range to bring out detail of the distribution
Compute the mean, median and standard deviation of the differences¶
Why might we have a non-zero mean/median difference?
Create a scatterplot of elevation difference glas_srtm_dh values vs elevation values¶
glas_srtm_dhshould be on the y-axisglas_zvalues on the x-axis
Extra Credit: Remove outliers¶
The initial filter in glas_proc.py removed GLAS points with absolute elevation difference >200 m compared to the SRTM elevations. We expect most real elevation change signals to be less than this for the given time period. But clearly some outliers remain.
Design and apply a filter that removes outliers. One option is to define outliers as values outside some absolute threshold. Can set this threshold as some multiple of the standard deviation (e.g., 3*std). Can also use quantile or percentile values for this.
Create new plot(s) to visualize the distribution of outliers and inliers. I’ve included my figure as a reference, but please don’t worry about reproducing! Focus on the filtering and create some quick plots to verify that things worked.
Active remote sensing sanity check¶
Even after removing outliers, there are still some big differences between the SRTM and GLAS elevation values.
Do you see systematic differences between the glas_z and dem_z values?
Any clues from the scatterplot? (e.g., do some tracks (north-south lines of points) display systematic bias?)
Brainstorm some ideas about what might be going on here. Think about the nature of each sensor:
ICESat was a Near-IR laser (1064 nm wavelength) with a big ground spot size (~70 m in diameter)
Timestamps span different seasons between 2003-2009
SRTM was a C-band radar (5.3 GHz, 5.6 cm wavelength) with approximately 30 m ground sample distance (pixel size)
Timestamp was February 2000
Data gaps (e.g., radar shadows, steep slopes) were filled with ASTER GDEM2 composite, which blends DEMs acquired over many years ~2000-2014
Consider different surfaces and how the laser/radar footprint might be affected:
Flat bedrock surface
Dry sand dunes
Steep montain topography like the Front Range in Colorado
Dense vegetation of the Hoh Rainforest in Olympic National Park
Let’s check to see if differences are due to our land-use/land-cover classes¶
Determine the unique values in the
lulccolumn (hint: see thevalue_countsmethod)In the introduction, I said that I initially preserved only two classes for these points (12 - snow/ice, 31 - barren land), so this isn’t going to help us over forests:
Use Pandas groupby to compute stats for the LULC classes¶
This is one of the most powerful features in Pandas, efficient grouping and analysis based on some values
Compute mean, median and std of the difference values (glas_z - dem_z) for each LULC class
Do you see a difference between values over glaciers vs bare rock?
Extra credit: groupby year¶
See if you can use Pandas
groupbyto count the number of shots for each yearMultiple ways to accomplish this
One approach might be to create a new column with integer year, then groupby that column
Can modify the
decyearvalues (seefloor), or parse the Python time ordinals
Create a bar plot showing number of shots in each year
Extra Credit: Cluster by campaign¶
See if you can create an algorithm to cluster the points by campaign
Note, spatial coordinates should not be necessary here (remember your histogram earlier that showed the number of points vs time)
Can do something involving differences between sorted point timestamps
Can also go back and count the number of campaigns in your earlier histogram of
decyearvalues, assuming that you used enough bins to discretize!K-Means clustering is a nice option: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
Compute the number of shots and length (number of days) for each campaign
Compare your answer with table here: https://nsidc.org/data/icesat/laser_op_periods.html (remember that we are using a subset of points over CONUS, so the number of days might not match perfectly)
Extra Credit: Annual scatterplots¶
Create a figure with multiple subplots showing scatterplots of points for each year
Extra Credit: Campaign scatterplots¶
Create a figure with multiple subplots showing scatterplots of points for each campaign